EventHub was designed to handle hundreds of events per seconds while running on a single commodity machine. With EventHub, you don’t need to worry about pricy bills. We did this to make it as frictionless as possible for anyone to start doing essential data analysis. While more details can be found from our repository, the following are some key observations, assumptions, and rationales behind the design.
Architecture Overview
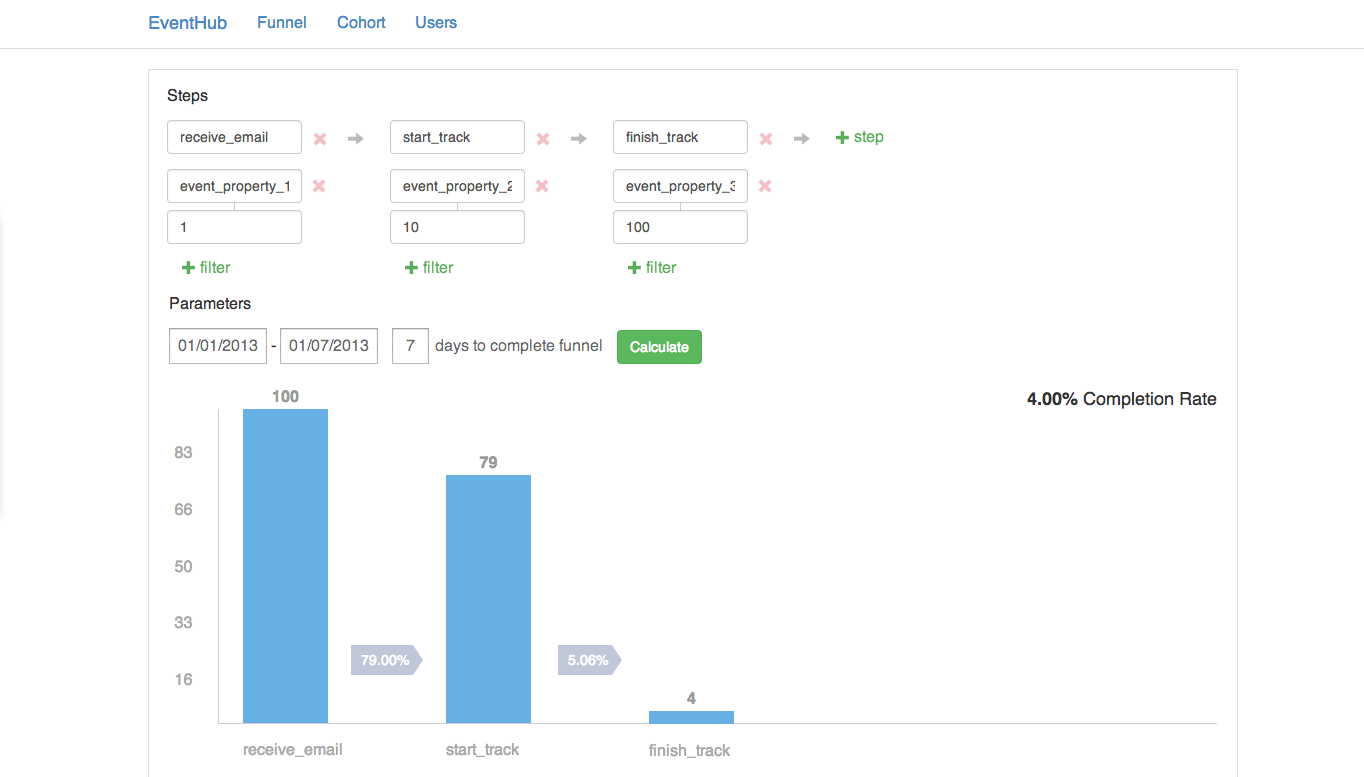
Basic funnel queries only requires two indices, a sorted map from (event_type and event_time) pair to events, and a sorted map from (user and event_time) pair to events
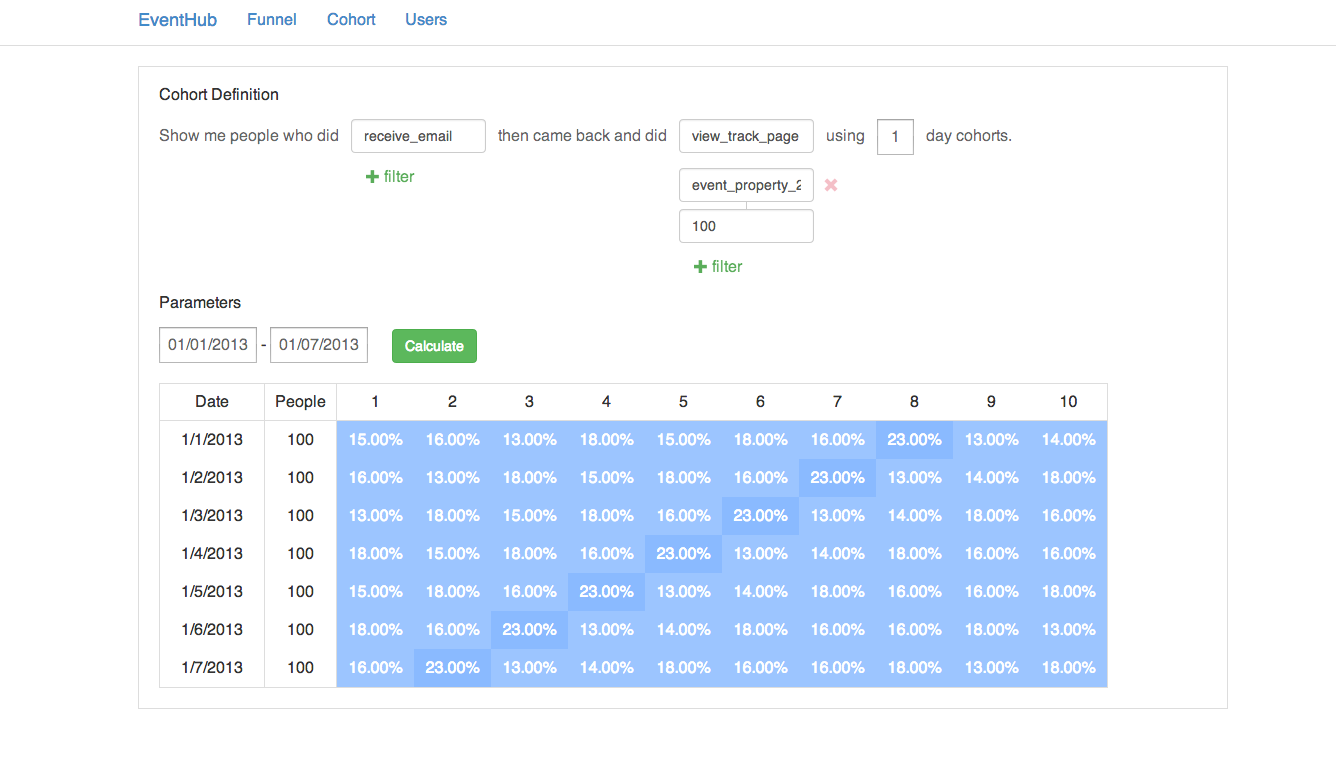
Basic cohort queries only requires one index, a sorted map from (event_type and event_time) pair to events.
A/B testing and power analysis are simply statistics calculation based on funnel conversion and pre-determined thresholds
Therefore, as long as the two indices in the first bullet point fit in memory, all basic analysis (queries by event_types and date range) can be done efficiently. Now, consider a hypothetical scenario in which there are one billion events and one million users. A sorted map implementation like AVL tree, RB tree, SkipList, etc. can be dismissed as the overhead of pointers would be prohibitively large. On the other hand, B+tree may seem to be a reasonable choice. However, since events are ordered and stored chronologically, sorted parallel arrays would be a much more space efficient and simpler implementation. That is, the first index from (event_type and event_time) pair to events can be implemented as having one array storing event_time for each event_type and another parallel array storing event_id, and similarly for the other index. Though separate indices are needed for looking up from event_type or user to their corresponding parallel arrays, as event_type and user are level of magnitude smaller than events, the space overhead is negligible.
With parallel array indices, the amount of memory needed is approximately (1B events * (8 bytes for timestamp + 8 bytes for event id)) * 2 = ~32G, which still seems prohibitively large. However, one of the biggest advantage of using parallel arraysis that within each array, the content is homogeneous and thus compression friendly. The compression requirement here is very similar to compressing posting list in search engines, and with algorithm like p4delta, the compressed indices can be reasonably expected to be <10G. In addition, EventHub made another important assumption that date is the finest granularity. As event id is assigned monotonically increasingly, the event id itself can then be thought of as some logical timestamp. As EventHub maintains another sorted map from date to the smallest event id on that date, all the queries filtered by date range can be translated to queries filtered by event id range. With that assumption, EventHub was able to get rid of the time array and further reduced the index size by half (<5G). Lastly, since indices are event_ids stored chronologically in an array, plus the array is stored as memory mapped file, the indices are very friendly to kernel page cache. Also, assuming most of the analysis only cares about recent events, as long as those tail of the indices can fit in the memory, most of the analysis can still be computed without touch disks.
At this point, as the size of the basic indices is small enough, EventHub would be able to answer basic funnel and cohort queries efficiently. However, since, there are no indices implemented for other properties on events, in case of queries filtered by event properties other than event_type, EventHub still needs to look up the event properties from disk and filter events accordingly. Due to the space and time complexity needed for this type of query is not easy to estimate analytically, but in practice, when we ran our internal analysis at Codecademy, the running time for most of the funnel or cohort queries with event properties filter is around few seconds. To optimize the query performance, the followings are some key features implemented and more details can be found from the repository.
Each event has a bloomfilter to quickly reject event property which doesn't exactly match the filter
LRU Cache for events
Assuming the bloomfilters are in memory, EventHub only needs to do disk lookup for events that actually match the filter criteria (true positive) as well as the false positive events from bloomfilters. As, the size of bloomfilters can be configured, the false positive rate can be adjusted accordingly. Additionally, since most of the queries only involves recent events, to optimize the query performance, EventHub also keeps a LRU cache for events. Alternatively, EventHub could have implemented inverted index like search engines do to facilitate fast equality filters. The primarily reason for adopting bloomfilters with cache is that it doesn't require adding more posting list as new event properties are added, and we believe for most use cases and with proper compression, EventHub can easily cache hundreds of million of events in memory and achieve low query latency.
Lastly, EventHub as is doesn't compress the index and we left that as one of our todo. In addition, the following two features can be easily added to achieve higher throughput and lower latency if that's needed.
Event properties can be stored as column oriented which will allow high compression rate and great cache locality
Events from each user in funnel analysis, cohort analysis, and A/B testing are independent. As a result, horizontal scalability can be trivially achieved from sharding by users.
As always, it's open sourced, and pull requests are highly welcome.
If you like the post, you can follow me (@chengtao_chu) on Twitter or subscribe to my blog "ML in the Valley". Also, special thanks Bob Ren (@bobrenjc93) for reading a draft of this